|
Hi! I am a PhD student at MIT, advised by Prof. Andreea Bobu. My research focuses on robot learning and robotic manipulation, particularly Vision-Language-Action (VLA) models and human-in-the-loop learning for robotic systems. Previously, I received my MS in Robotics from Carnegie Mellon University, where I worked with Prof. Zackory Erickson on shared autonomy and assistive robotics. I obtained my bachelor's degree from Wuhan University, where I worked with Prof. Zhenzhong Chen on computer vision research. Email / CV (Last updated: Mar. 2026) / Google Scholar / LinkedIn / Github |

|
|

|
My current research focuses on robot manipulation and learning with Vision-Language-Action (VLA) models. I am interested in improving the robustness and controllability of VLA policies for real-world robotic tasks. My current work explores how VLA policies represent and execute multiple valid manipulation strategies in real-world tasks. I am also interested in how modifying robot observations before they are processed by VLA policies—such as removing distractors or simplifying scenes—can improve policy reliability without additional fine-tuning. An early prototype experiment (developed as part of a course project) can be seen here: Video |
|
|
|
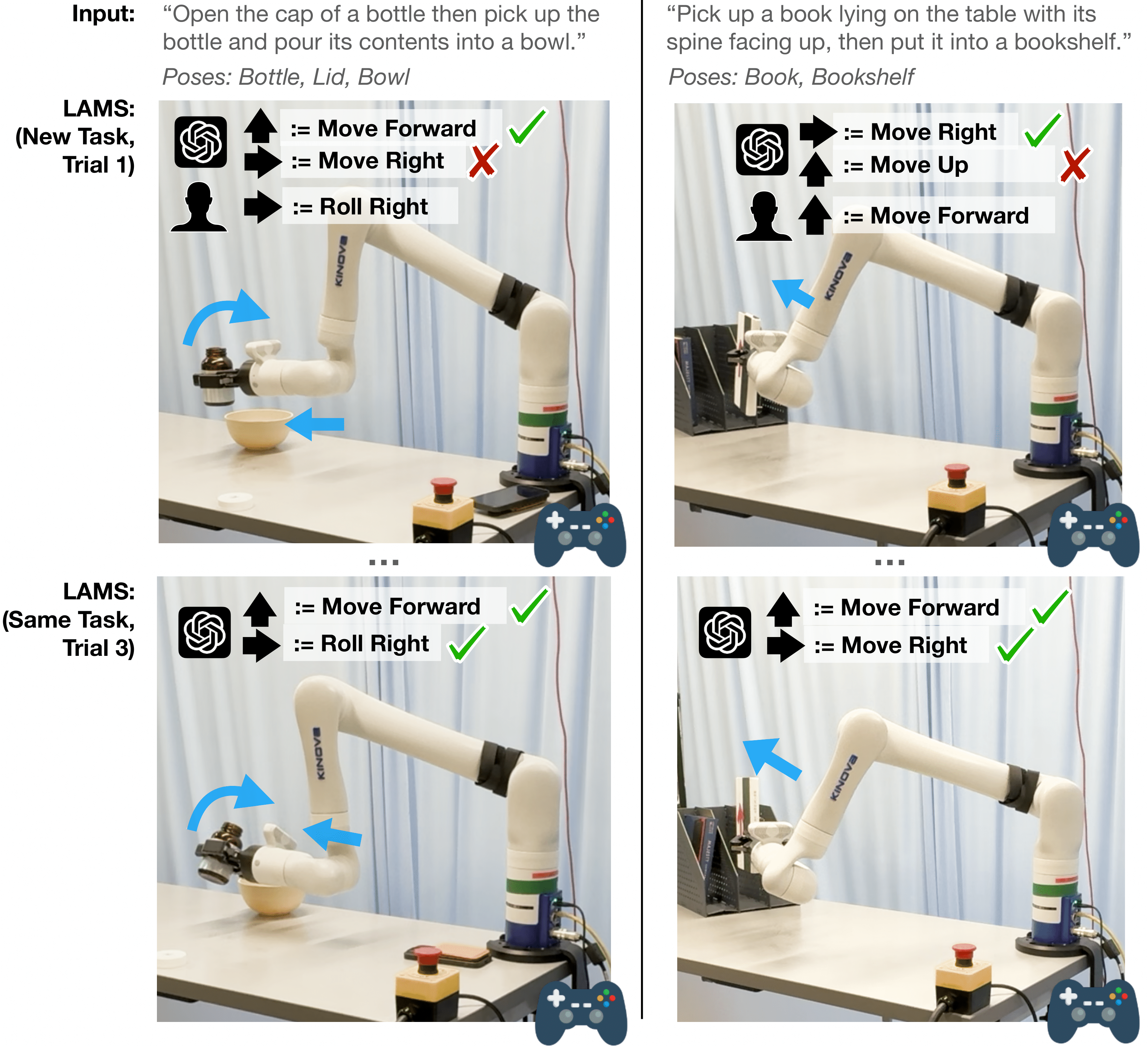
Yiran Tao*, Jehan Yang*, Dan Ding, Zackory Erickson HRI 2025 (Best Paper Finalist) We introduce LLM-Driven Automatic Mode Switching (LAMS), a method that automatically switches robot control modes based on task context using large language models. |
|
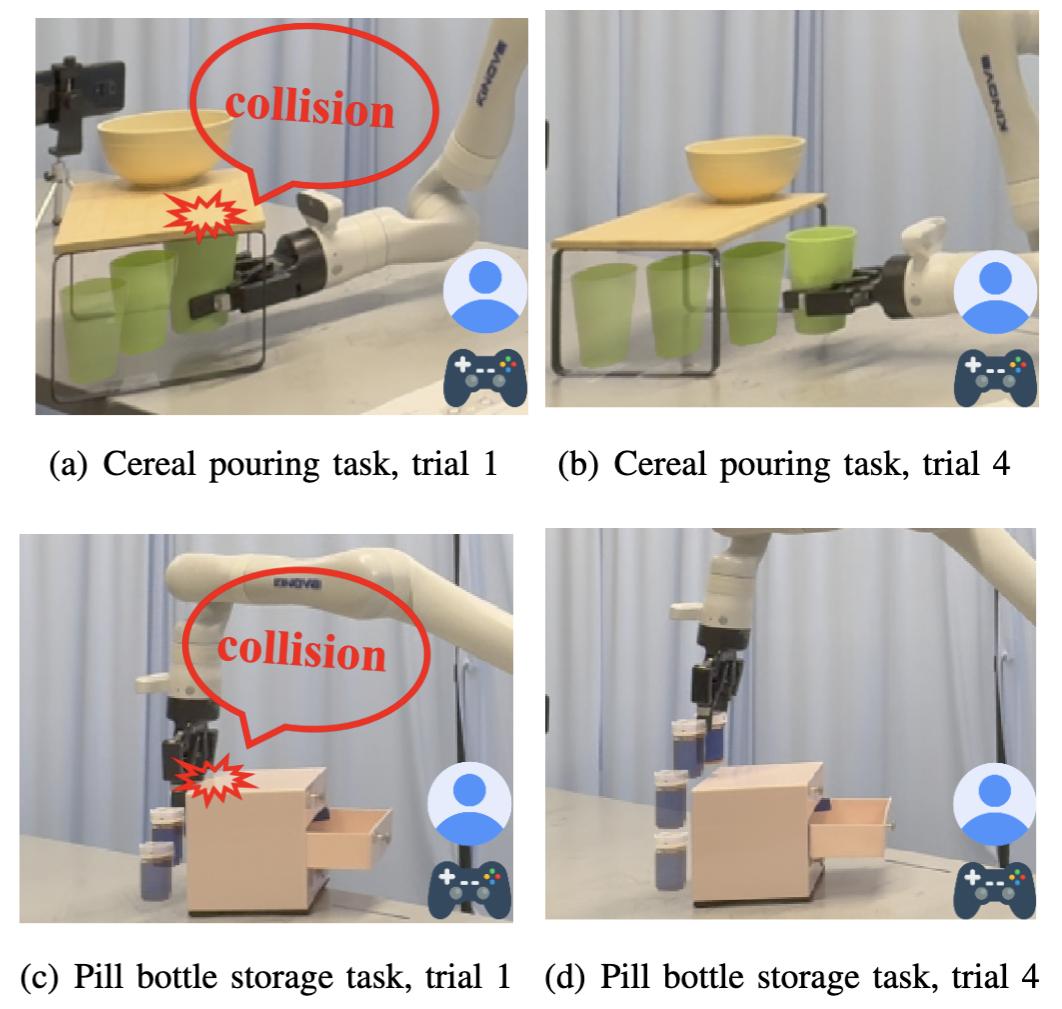
Yiran Tao, Guixiu Qiao, Dan Ding, Zackory Erickson IROS 2025 We introduce ILSA, an Incrementally Learned Shared Autonomy framework that continually improves its assistive control policy through repeated user interactions. |
|
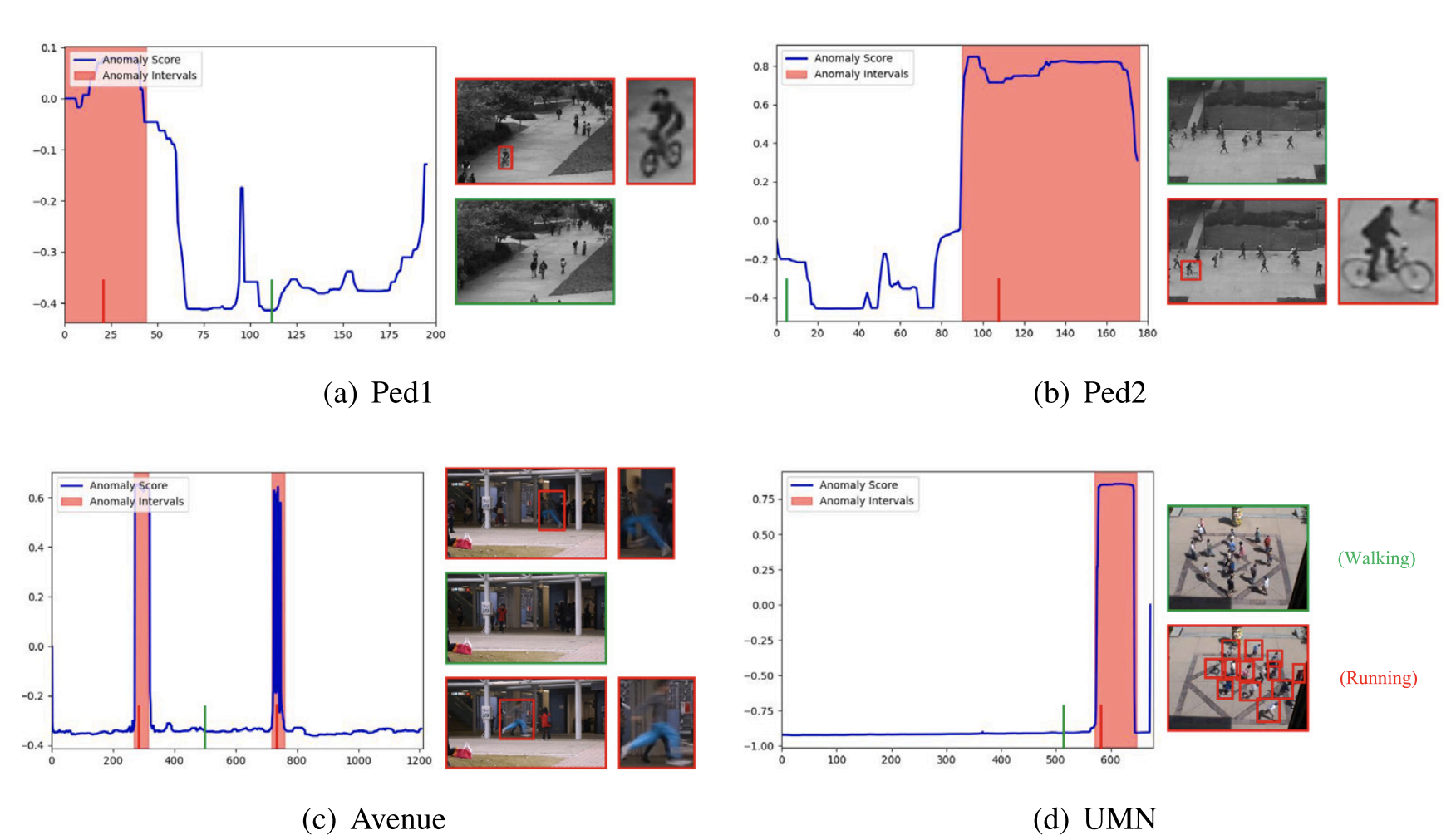
Yiran Tao, Yaosi Hu, Zhenzhong Chen Journal of Visual Communication and Image Representation |

|
Weijian Ruan*, Yiran Tao*, Linjun Ruan, Xiujun Shu, Yu Qiao IEEE Signal Processing Letters |

|
Yiran Tao, Yaosi Hu, Zhenzhong Chen IEEE VCIP 2021 |
|
Last updated: Mar. 2026 | Template from Jon Barron |